
记忆化搜索
前面已经提到了,我们在搜索的时候,有时候多个状态会指向同一个状态。
比如,把整数
那么前两个数字不管是
所以我们可以进行记忆化,就是在第一个到达
int dfs(int n,int k)
{
if(k==0)
{
return (n==0);
}
if(dp[n][k]!=-1) return dp[n][k];
int ret=0;
for(int i=1;i<=n;++i)
{
ret+=dfs(n-i,k-1);
}
dp[n][k]=ret;
return ret;
}这里,dfs 的参数有两个,取值范围分别是 1~n 和 1~k 。
dfs 内部还有一个循环,所以总时间复杂度
这样也可以改成递推的形式:
dp[0][0]=1;
for(int i=1;i<=k;++i)
{
for(int j=0;j<=n;++j)
{
for(int x=1;x+j<=n;++x)
{
dp[x+j][i]+=dp[j][i-1];
}
}
}但是在有些情况下,递归比递推更容易表示出来。
动态规划(DP)
动态规划可以解决一些只顾眼前利益的贪心解决不了的问题。
比如,有
对于三颗宝石,(价格,价值)分别为:
不管是先取价值最大的,还是先取性价比最高的,都选不到最优解(选后两个)
更不用说宝石更多时,情况更复杂。
怎么办呢,不能在当前选择时决定的情况,我们就把它加入到状态里去。
比如说,对于第一颗糖,它的价格是
如果要他,那么现在花了
如果不要,那么现在花了
然后对于下一个物品,假设价格是
前面我们有花了
花
花
这个不就是枚举每个物品要还是不要吗,那这样复杂度不就变成
假设下一个物品,价格是
那么我们现在有四种情况:
假如我现在在
但是
也就是将情况合并,只保留最好的结果。
所以这时候,一共只会保留下花了
例题一
设
每个位置可以从上一行的这一个,或者上一行的左边一个转移过来。
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1])+a[i][j]
最后答案是 max{dp[r][i]}
DP三要素
1.最优子结构性质
即目前局面的最优解的通过某个抉择,从之前局面的最优解得到的:
比如上面的数字三角形问题:
dp[i][j]=max(dp[i-1][j],dp[i-1][j-1])+a[i][j]
dp[i][j] 的最优解是从 dp[i-1][j-1] 和 dp[i-1][j] 其中之一的最优解,再通过一步抉择得到的。
如果 dp[i][j] 的最优解不能通过之前的最优解得到,那么问题就复杂了。
2.无后效性
确定转移顺序后,当前问题的最优解只和之前已经确定的局面有关。
比如上面的数字三角形问题:
当你按行去转移,枚举到 dp[i][j] 的时候,dp[i-1][j] 和 dp[i-1][j-1] 的值已经确定不会变了。
dp[i][j] 的值只和已经确定的 dp[i-1][j] 和 dp[i-1][j-1] 有关系。
如果 dp[i][j] 的值同时和 dp[i+1][j],dp[i-1][j] 有关系,那么不管怎么转移,dp[i][j] 都有后效性,就没办法动态规划了。
无后效性也可以理解为,如果把状态抽象成节点,把转移抽象成节点之间的一条有向边,那么这张图是有向无环图(DAG)。
可以想象,如果这张图上有环,那么环上节点的信息通过转移永远也不能确定下来。
有向无环图和动态规划问题因此可以互相转化。
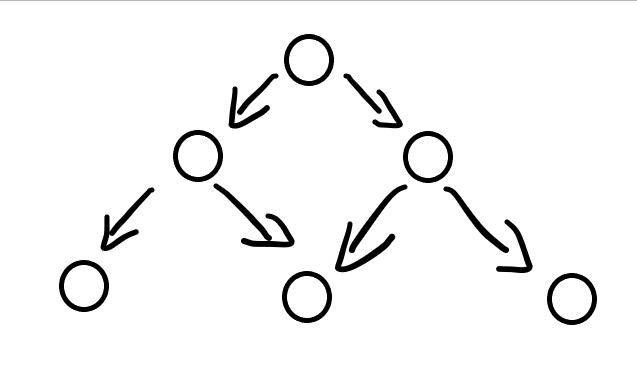

3.缩小问题规模
当你做出一步觉得后,接下来要解决的问题和之前要解决的问题类似,只是问题规模变小了。
比如
例题二:
有
怎么做呢,对于第
DP常用方案:对于有后效性的部分,把它加进状态里!
设 dp[i][0/1]表示,已经处理了i 个位置选还是不选。
dp[i][0] 表示第dp[i][1] 表示第 i 个位置选的最大值。
既然有后效性,那就把方案都记录下来。
当我们处理下一个位置时:
dp[i+1][0]=max(dp[i][1],dp[i][0]):如果下一个位置不选,这个位置选不选都行。
dp[i+1][1]=dp[i][0]+a[i+1]:如果下一个位置选,这个位置只能不选了。
答案就是 max(dp[n][0],dp[n][1])
练习题
P1020 [NOIP1999 普及组] 导弹拦截 用到了二分优化和最小链覆盖等与最长反链