
欢迎来到算法的世界
0.安装编译器
为了省去逆天的配置操作,我们用最简单的 dev-c++ 进行演示:
安装包在迎新群里有,名字叫 Dev-CPP 5.9.2。

运行安装包之后:
这里只有英文没关系啊,这里是安装时的语言,安装好了之后有中文的。
选 OK:

(你爱我吗)选 I Agree:
选 next:
选个你喜欢的安装路径,因为这玩意不用配置文件,所以随便装哪都没事,然后Install:

选 Finish:

如果你进去之后是英文的,在上面一栏的工具(tool)这个地方,点第二个环境选项(Environment option),选中文:

编译器装好了,在上面一栏的文件这里,选择新建->源代码,或者用快捷键 Ctrl+N新建一个文件,建完之后就会出现一个未命名1:

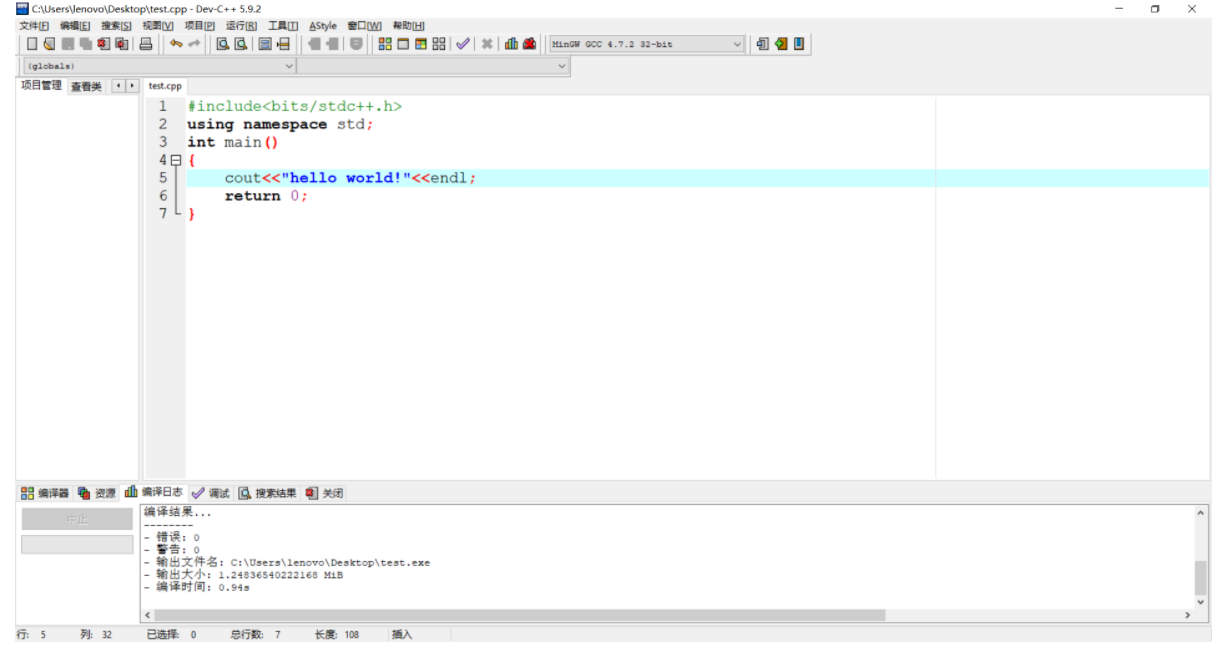
在里面填入以下代码:
#include<bits/stdc++.h>
using namespace std;
int main()
{
cout<<"hello world!"<<endl;
return 0;
}
填入之后还不能运行呢,在文件那里保存以下这个文件,或者是用快捷键 Ctrl+S保存一下这个文件。
会弹出这个保存框,保存的地点自己选,文件名中前面自己随便改,后面的.cpp后缀要保留,否则这就不是一个可以编译的文件了。

保存成功之后,点这里的编译运行,或者摁快捷键 F11:

成功编译运行,输出了hello world!:

恭喜你的第一份代码运行成功,你的世界自动触发开启隐藏主线任务:程序员。
1.认识程序结构
代码中,以;来作为一行的结尾,遇到分号则表示这一句话结束。
abc;
ab
cd;上面的例子中,一共只有两句话,第一句话是abc,第二句话是abcd。
#include<bits/stdc++.h>
using namespace std;
int main()
{
cout<<"hello world!\n";
return 0;
}回顾刚才编译成功的代码,我们来逐条解释:
#include<bits/stdc++.h>这个的意思是,接下来我要写的代码,要用到头文件<bits/stdc++.h>里面的工具。
比如说,我们把编程比作写数学题,我们可以能要用到一个叫勾股定理的东西,这个叫勾股定理显然不是我们自己发明的(不然你每次做数学题都要从数字的定义来开始写吗?)而是我们可以直接拿来用的。
同样的,编程也是,不是所有的功能都要自己来实现(比如读取数据、输出数据等),有些功能是被前辈们实现好的,他们就储存在各式各样的头文件里面,只要我们include了指定的头文件,就可以直接用这些写好的功能了。
假如,勾股定理存在在一个叫math的头文件里,我们在代码在最前面写下#include<math>,就可以在后面直接使用勾股定理,而不用去证明它是对的。
第二行:
using namespace std;使用 命名空间 std。
命名空间中也是一些功能的存在,和头文件里的功能储存方式不同,但是一开始不需要分辨,只需要知道这里面也是各种功能。
第三行:
int main()
{
abc;
def;
return 0;
}这个被称为主函数。每一个程序,当他开始运行的自己的功能的时候(也就是说不算之前调用写好的功能),第一句话从主函数里面开始,也就是说第一句执行的语句是abc。
这个代码中,除了abc;和def;以外的语句,都是主函数的形式,这个形式的具体解释需要用到函数方面的知识,所以先把框架放在这里,后面再进行解释。
cout<<"hello world!"<<endl;这句话的功能是在屏幕上输出 hello world! 并换行。
为啥写这句话就能进行输出呢?
因为前面调用的 #include<bits/stdc++.h> 和 using namespace std; 帮你实现了这个功能!
输出语句的格式是这样的:
首先,写一个 cout ,表示你要输出东西。
然后,写一个 <<,表示后面是要输出的内容。
然后,写下你要输出的内容 "hello world!",输出的内容要用双引号框起来。
双引号框起来的内容叫字符串,在输出中,表示这里面的内容要原样输出,没有任何指代含义。
然后写分号,表示这句话结束。
合起来就是
cout<<"hello world";唉后面还有一半呢。
如果你想一次输出多个内容,不用写多个 cout,只要在前面不写分号,然后再写一个<<,后面接输出内容就行了。
比如
cout<<"hello "<<"world!";这样也可以输出 hello world!。
如果你的输出想换行,就在输出内容那里写endl,它表示换行的意思,这个不加双引号。
cout<<"hello world!"<<endl;如果你的 endl 也加了双引号,那它就不认为这是换行了,它认为你要输出这四个字母,最后就会给你输出一个 hello world!endl 这个东西了。
最后一句
return 0;是主函数结束的标志,读到这句话,主函数就结束了,后面写的语句将被无视。
总的来说,在新手期,程序的基本框架就是
#include<bits/stdc++.h>
using namespace std;
int main()
{
//在这个地方写东西,其他的别动。
return 0;
}2.变量、赋值、输入、输出。
在说明之前,我们写的内容都是在上面代码中给定的地方,其他的代码默认不动。
我们的计算机初心是为了更快的计算,而计算就要有数字,我们现在还没说怎么得到数字呢。
计算机的数字是通过变量来表示出来的,变量的得到形式是 int a; 。
它的意思是,定义一个整数类型的变量,名字叫 a,其中 int 表示这个变量是整数类型,a 表示变量的名字叫 a。
通俗的讲,我找来了一个盒子,这个盒子专门装整数,我给这个盒子取名叫 a,一个盒子同时只能装一个整数。
我想把数字 3 放到 a 盒子里。
在程序里,方法是 a=3;。
这里的等于号不是指左右两边相等,是指把右边的数字放到左边的变量里面,= 代表的含义是赋值。
= 左边必须是一个变量,右边必须是一个可以算出来数字的式子。
过了一会,我又想把数字 5 放到 a盒子里。
那就改成 a=5;
在之后的代码中,只要提到单独的 a,那么就代指 a 里面的数字。
比如我们写了
cout<<a<<endl;最后会输出一个 5 ,因为 a 是一个变量,这里的 a 指的是它里面的数字。
如果你想输出 a 这个字符,请加双引号。
如果你定义了变量,而没有赋值,就等于拿了个盒子过来,而没有规定里面是什么
赋值这个符号也可以玩出花的,比如,我们现在有两个变量
int a=3,b=5;
怎么才能交换两个变量里面的值呢?
交换两个盒子里的数字,可以先找来第三个盒子 c ,先把 a 里面的东西放到 c 里面,再把 b 里面的东西放到 a 里面,再把 c 里面的东西放到 b 里面。
int a=3,b=5,c=a;
a=b;
b=c;但是如果是普通的盒子,你或许可以先把 a 里面的数字放到 b ,再把 b 里面的数字放回 a。
而这个盒子有一个特性,同一时间里面只能存在一个数字,当你把 a 里的数字放进 b ,那么原来数字 b 里的值就被覆盖了,不知道原来是多少了。
如果是日常做题,你发现 a=3,b=5 ,那只要反过来赋值,让 a=5,b=3就算交换了。
而在计算机中,你设计的题目不仅仅是为了解决这一种情况。
上面这种方法,不管 a ,b 是多少,都能把它们的值进行交换。
把上面这个问题拓展成一个比较一般的情况,随便输入两个变量,交换这两个变量的值。
这里用到一个输入,写法和输出类似。
当你要输入的时候,先写一个 cin。
然后在要输入的地方写一个 >>,后面接要输入的值。
int a,b,c;
cin>>a>>b;//从键盘上输入数字 a,b
c=a;
a=b;
b=c;这里的 cin 就是输入的意思,从键盘上输入变量 a,b 中的值。
这里输入可以看作是,往某个你已经拿来的盒子里放一个数字进来,所以输入的 >> 后面必须接一个能装填数字的变量。
这里 // 后面的内容是注释,就是解释代码的含义,在 c++ 中, // 后面的内容只能读代码的人看到,编译器会直接忽视它。
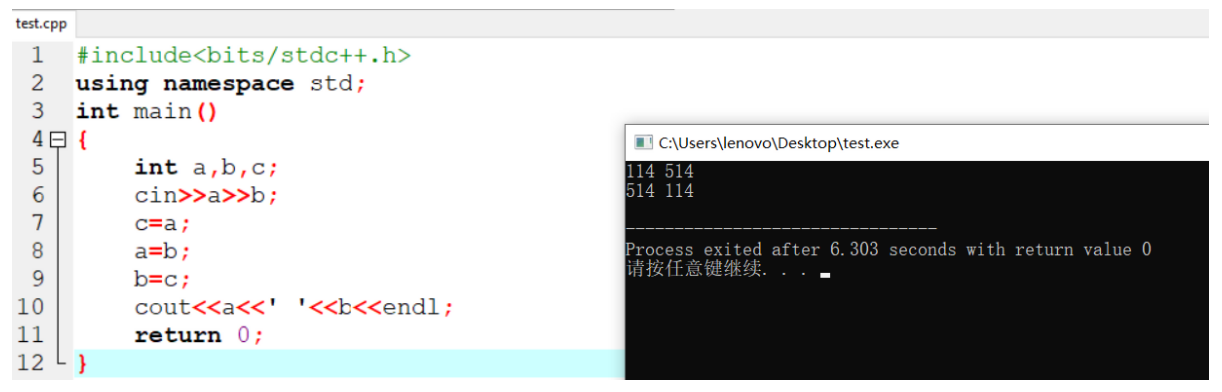
例如,在写了这份代码,编译运行,在黑框中输入了 114 514。
然后程序读到两个输入的变量,开始执行,最后输出了 514 114。
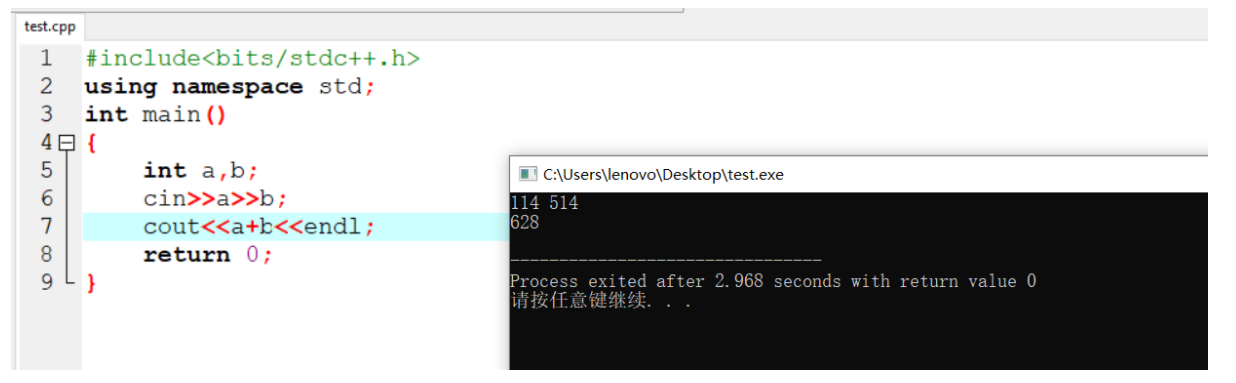
再举个例子:输入两个数字,输出它们的和:
思考题:尝试一下不借助额外的变量,交换 a,b 的值。
3.各种数据类型
因为存储一个数字,是需要空间的,比如你需要一个盒子来放整数,那你拿的盒子肯定不会是无限大的,所以这个盒子能放的数字也是有范围限制的。
比如说,你需要一个盒子,用来装 100 以内的自然数,那我给你一个能装 -200~200 的盒子就差不多了,再大就浪费了。
但是如果你想装 10000 以内的自然数,我就要给你换大盒子了。
short 类型的变量:存的数字的大小范围是
int 类型的变量:存的数字的大小范围是
long long 类型的变量:存的数字的大小范围是
还有一些特殊的类型:
bool 类型变量:只能存 0 或者 1 ,0 代表结果为假,1 代表结果为真。
这个 bool 类型适用于只需要判断两种情况的时候,比如你投一个硬币,只想知道哪面朝上,可以定义一个 bool flag;,在 flag 里面存投硬币的结果。
char 类型变量:用来存字符类型的变量,数值范围是
为什么字符类型还有数值呢?
计算机中,比如你想存一个字符 x,但是计算机只有 0/1 格子,它只能存数字,所以计算机是靠每个字符和一个数字来对应(对应规则常用的是 ASCII码),在字符变量中存储数字实现的。
比如,x 和 120 对应,那么你写 char ch=x; 的时候,变量 ch 里面真正存的其实是数字 120,而 char 解释了这是一个字符类型的变量,所以当你对 char 输入 x 的时候,它自动把 x 对应成 120 放进 ch ,当你要输出 ch 的时候,它又自动把 120 解释为 x 进行输出。
如果你在代码中,只写一个 x ,那么一般代表的是有个变量的名字是 x。
如果你想指的是字符x,那么请加单引号 'x'。
char x,y;
y='b';
x=y; // 这时候 x 里面是 'b'。
x='y' // 这时候 x 里面是 'y'。
char ch=120;
int num=120;
cout<<ch<<' '<<num<<endl;
//输出结果是:x 120string 类型变量:字符串类型,里面存的是由许多个char 拼接成的字符串,每个字符也遵守对应规则。
如果不想表示变量,而想表示字符串,请加双引号。
string ab,cd;
cd="qaq";
ab=cd; //此时 ab 里面是 "qaq"。
ab="ac"; //此时 ab 里面是 "ac"。double 类型变量:用来存储小数,没有范围限制,但是当你存的数字过大或者过小时,会产生一定的误差。
如果想要输出一个小数,可以用下面的句子来控制输出小数点后多少位数:
double a=1.234;
cout<<fixed<<setprecision(2)<<a<<endl;这样最后就只会输出 1.23。这个控制遵循四舍五入原则。
4.运算符
+ 两个数字或变量或式子的结果相加,没啥好说的。
- 两个数字或变量或式子的结果相减,没啥好说的。
* 两个数字或变量或式子的结果相乘,没啥好说的。
/ 左边的变量除以右边的变量,并得到不大于结果的最大的整数值(或者说,把小数部分、余数部分都舍去,只保留商)。
比如 7/3 得到 2。
% 取模,左边的变量除以右边的变量,得到的余数,与乘除同一优先级,只能对整数操作。
比如 7%3 得到 1,因为 7/3=2……1。
取模通常是有用的,比如求一个数字的个位数是多少,直接将这个数字对 10 取模,就可以得到答案。
= 右边的值赋值给左边的数字。
这个也有注意事项,比如 a=b/c。
如果 a 是 double ,b,c 是 int ,而且 b=5,c=2 呢?
因为 a 可以存小数,所以 a 里面应该是 2.5 吗?
其实不是因为 = 的运算顺序是,先把右边的数字给算出来,而右边的数字在运算过程中,没有任何小数参与其中,所以得到的结果是整数类型的。
也就是,先算出了 b/c 得到 2 ,然后再把 2 放入 a 中。
解决办法是 a=(double)b/c。
这个办法是强制类型转化,可以强行把 b 变成 double 类型,这样右边参与运算的数字中有了小数类型,结果就会保留成 2.5。
或者可以是 a=1.0*b/c。
注意:
double a,b=2.0;
int c=5,d=2;
a=c/d*b;这样 a 最后的值是 4.0。因为除法和乘法同一优先级,所以还是先算了 c/d 的值,然后再把算出来的值和 b 相乘,就变成 2*2了。
++ ,自增运算符,在一个变量前或者后都可以,写成 a++; 或者 ++a;。
两者还是有区别的:
int a=3,b;
b=a++; //等价于 b=a,a=a+1;
b=++a; //等价于 a=a+1,b=a;分不清的话,不写就完了,这玩意也不是必须要写。
-- ,自减运算符,跟上面一样。
对于各种运算语句,有一种特殊的缩写方式:
a+=b 等价于 a=a+b
a*=b 等价于 a=a*b
这个法则对于 +,-,*,/,% 和将来要学的位运算 &,|,^,<<,>>都适用。
对于自增 ++ 和自减 -- 暂时不适用。
上面提到的所有的语句,都是顺序结构的,你将语句们一条一条的写出来,用 ; 隔开,计算机就从头到尾一条一条执行。
5.练习方法
洛谷网站比较常用,上面有很多练习题:
注册登录洛谷之后,点击左侧的题单

洛谷这个题单并不太适合新手自己做,但是看完这章先做入门123还可以,建议做完之后问问学长应该练习哪里。
点开顺序结构,题目列表之后,会出现很多题目:

点开第一个题:

可以看到有样例输入输出,意思是,根据题目要求,你的代码在输入左边的之后,应该输出右边的结果(这个题特殊,不用进行输入),如果你的输出结果和右边不符,就是代码写错了。
当然如果相符也不一定代表你全写对了,这个样例只是一个例子,你设计的算法应该是能解决一类问题,而不是这一类问题中的某一个情况。
如果写完了交答案,点左上角的提交答案,然后会出现一个框,把代码完整的复制进去,提交就行了。
语言可以选自动识别,或者 C++17。
如果有题目不会做,可以点击右边的查看题解(也可以找学长学姐问)。
当你提交之后,过几秒时间和给你代码评测结果,AC 代表答案正确, WA 代表答案错误,其他的情况之后再细讲,反正也代表答案错误,需要修改代码。
如果有的是 AC 有的是 WA 以及其他,说明代码在有的情况下是正确的,有的情况下是错误的,也需要修改代码,到全部 AC 为止。
另一个练习方案是看群文件里的《信息学奥赛一本通》,这本书也讲的很好课后有练习题,练习题提交网址在这里 http://ybt.ssoier.cn:8088/index.php
练习方式和上面的类似,不重复讲了。
练习题:
6.判断
如果我们要根据不同的数据选择不同的结果呢,比如看见红灯选择闯,看见绿灯选择等。
上面普通方法不能实现这个功能,必须要有一个能够进行判断,并做出不同行为的语句。
语句是这样的:
if(/* 判断条件 */)
{
//条件成立,执行这里的内容
}
else
{
//条件不成立,执行这里的内容
}举个例子,判断一个数字是不是偶数:
int a;cin>>a;
if(a%2==0)
{
cout<<"是偶数"<<endl;
}
else
{
cout<<"不是偶数"<<endl;
}成立和不成立范围内的代码要用花括号框起来,防止和外面的部分混淆。
如果没有花括号做区分,那么默认只有 if 后面一句话(以;为准)是判断条件内部的语句。
注意 if 里面的内容,是不是偶数就看 a 除以 2 的余数就可以,判断这个余数是 0 还是 1 ,而我们判断这个余数是不是 0 ,用的是 ==,因为 = 是赋值符号,在 c++ 里, == 才是判相等的符号。
一些其他的符号:
< 是否小于
<= 是否小于等于
> 是否大于
>= 是否大于等于
== 是否相等
!= 是否不相等
上面代码中的 else 可以省略不写,只写 if 部分。
注意一个坑点,不要把 == 写成 = ,因为写成 = 也可以通过编译,而且不会报错。
int x;cin>>x;
if(x=5)
{
cout<<"yes";
}如果你这么写,就会先把 x 赋值成 5,然后判断 5 这个数字,当单独判断一个数字的时候,如果这个式子不等于零,则认为条件成立,否则认为条件不成立,所以这时候不管输入什么,都会输出 yes 。
如果不只有一个判断条件,用以下符号连接起来:
&& 并且,左右两边的条件同时成立,整个式子才成立,比如 a 是偶数且大于 4 ,表示为 if(a%2==0&&a>4)
|| 或者,左右两边的条件只要有一个成立,式子就成立,比如 a 是偶数或大于 4,表示为 if(a%2==0||a>4)
! 取反,表示感叹号后面的式子的成立性取反,比如a 不等于 5 ,表示为 if(!(a==5))。
如果判断条件比较复杂,需要这几个符号组合,怎么记住它的优先级呢?
你记它干嘛,你想让哪个式子先判断,就在外面加个小括号。
if(a>5||(b>=3&&b<=5))这个式子的含义是 a 大于五,或者 b 在 3~5 范围内。
特别注意:if 小括号后面是没有分号的,如果加了,就不会认为 {} 是 if 的一部分了,那么 {} 不管怎样都会按顺序执行到里面的内容。
P5709 【深基2.习6】Apples Prologue / 苹果和虫子
7.循环
计算机主要是为了解决重复工作,要是每个式子都得亲自去写,那不得累死。
所以计算机中有循环,可以多次做重复工作。
循环方式有很多种,挨个说
第一种:
while 循环,跟 if 的方式类似。
在 if 语句中,先判断条件是不是成立,如果成立,则进入第一个花括号中,按顺序执行语句,执行完毕跳出花括号,执行下一句。
在 while 中,不同之处是,执行完花括号中的语句,回到判断条件,如果成立,再执行一次,如果不成立,跳出花括号

因为每次执行完都会回到判断,所以一般要设置一个条件,在循环一定次数后,能结束循环。
比如,我们要输出 10 个 a。
int cnt=1;
while(cnt<=10)
{
cout<<'a'<<endl;
cnt=cnt+1;
}这样,在循环 10 遍之后,就不满足 cnt<=10 了,循环就会结束。
第二种:
do
{
//执行语句
}while(/*判断条件*/)这种和第一种的区别是,第一种如果条件不成立,会直接不进行循环里的内容。
这种不管条件成立不成立,先执行语句一次,然后再进行判断,如果成立重新执行,不成立则结束。
这种和上面类似,而且不常用,不多讲了。
第三种:
for 循环,与前面不大相同。
for(int i=1;i<=10;++i)
{
cout<<'a'<<endl;
}这个语句也能做到输出十个 a 的要求。
for 的执行逻辑是这样的:

这里大致按编号顺序执行,没有加说明文字的箭头就是,做完自己的地方就做下一个。
刚开始,先进行(1)的语句执行,执行完毕后,进行(2)的判断条件,如果成立,执行(3)的语句执行,如果不成立,跳出(5)。
(3)执行完之后,进行(4)的语句执行,(4)执行完之后,回到(2)判断条件。
for(int i=1;i<=10;++i)
{
cout<<'a'<<endl;
}结合这里讲就是,先定义一个变量 i=1 ,然后判断 i<=10 ,然后执行 cout<<'a'<<endl;
然后执行 ++i ,再判断 i<=10。
这样的好处是,给出了专门的定义控制循环次数的变量的位置(1),和操作循环次数的位置(4),可以把循环相关的东西都放在 for 后面,而花括号里面只用写真正的执行语句。
第二个注意的地方是,我们关注到 if 和 for 里面都有花括号,花括号相当于一个小的独立区域。
这个怎么解释呢:比如
{
int a=1;
}
cout<<a;你这样写,编译器会报错,说你没有定义过变量 a。
这是因为,花括号里面定义的变量,只能在花括号里面使用,在遇到右括号的时候,之前定义的变量全部销毁不存在了。
在循环语句中,连带 for 语句后面小括号里的内容,都属于 for 的一个小独立区域的范围。
for(int i=1;i<=n;++i)
{
}
cout<<i;这样也会报错,因为 i 只在 for 的区域内存在。
但是花括号内是可以用在之前的外面定义的变量的。
int a=5;
for(int i=1;i<=n;++i)
{
cout<<a;
}这样是可以的,因为可以认为外面是花括号的上级,如果在花括号内没找到变量 a ,就会去外面找。
int a=5;
for(int i=1;i<=n;++i)
{
int a=3;
cout<<a;
}所以根据上面的逻辑,如果你在花括号里面也定义了变量 a ,输出的时候会优先认为 a==3。
也就是里面定义的 a 可以和外面定义的 a 不是一个东西。
就好像有一个 a 名字的箱子,你房子里的和你卧室里的不是一个东西。
但是这样会报错,重复定义:
int a=5;
int a=3;
for(int i=1;i<=n;++i)
{
cout<<a;
}所以,一个区域内不能定义多次同一个变量,而不同区域可以分别使用。
特别注意:while() 和 for() 的小括号后面也没有分号,原因同上。
对于上面有疑问的地方,先写个代码验证一下,看看跑出来是什么结果,还不理解就找学长学姐们问一下。
循环可以里面套用循环,注意不要两层循环的变量名混着用:
for(int i=1;i<=100;++i)
{
for(int j=1;j<=i;++j)
{
cout<<i*j<<' ';
}
cout<<'\n';
}循环里的特殊语句:
continue:跳过单次循环。
例如:求 n 的所有因子
for(int i=1;i<=n;++i)
{
if(n%i!=0) continue;
cout<<i<<endl;
}如果 n 不是 i 的倍数,则跳过本次循环,判断下一个数字,否则输出这个数字。
这里的 continue 是跳到 ++i 部分。
break :结束循环。
例如:判断 n 是不是质数
bool isprime=1;
for(int i=2;i<n;++i)
{
if(n%i==0)
{
isprime=0;
break;
}
}如果 2~n-1 中有一个数字能整除 n ,则根据定义 n 不是质数,那么剩下的数字就没必要再判断了,可以直接结束循环。
这里的 break 是直接跳到 for 语句后面的的花括号 {} 之外。
这两个语句一般都是配合 if 语句使用的,根据不同的条件执行。
P1217 [USACO1.5] 回文质数 Prime Palindromes 这个题要动点脑子,不要挨个枚举数字然后判断,否则你会得到超时。
8.输入输出效率
如果你遇到了 TLE 标志,那么说明你运行超时了,试着降低代码中循环的运行次数,或者像下面这样优化效率:
C语言中的输入输出:
int x,y;
scanf("%d%d",&x,&y);
printf("%d %d\n",x,y);其中scanf 是输入函数,其中输入两个整数要用两个占位符 %d占位,然后在后面分别写入要读入的变量名字,用逗号隔开。
变量名字前面要加 &。
printf 是输出函数,第一个双引号里面是字符串的意思,字符串中的内容都会原样输出,如果要输出变量,也要用占位符 %d 表示,表示这里要输出一个变量,变量按顺序在后面写出来,用逗号分隔。
其中双引号里两个 %d 中间的空格就是单纯的两个变量中间隔一个空格的意思,后面的 \n 是换行的标识符。
对于不同的类型,有不同的占位符,比如 int 类型是 %d ,long long 类型是 %lld。
这种方法比较麻烦。
C++:
int x,y;
cin>>x>>y;
cout<<x<<y<<endl;更方便,不用考虑格式和变量的类型。
一般情况下cin很费时间,因为 c++ 为了兼容 c 语言设置了一个缓存区,可以手动解除这个缓冲区绑定:
加入代码:
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);就可以让cin和scanf一样快,但是注意不能cin,cout和scanf、printf、putchar、puts等混合使用。
也就是说,加上解绑之后,只用 cin 和 cout 就可以了,不需要也不能再用 scanf 等。
之前的换行语句是这样的:
int a,b,c,d;
cin>>a>>b;
cout<<a+b<<endl;
cin>>c>>d;
cout<<c+d<<endl;先输入两个数字,比如3 5 摁下回车就会出现 8。再输入 10 20 摁下回车就会出现 30 。
如果改成这样:
int a,b,c,d;
cin>>a>>b;
cout<<a+b<<'\n';
cin>>c>>d;
cout<<c+d<<'\n';先输入两个数字,比如3 5 摁下回车,什么都不会出现。再输入 10 20 摁下回车,会出现两行,第一行是 8 ,第二行是30。
所以 endl 比一般换行操作还多了一个清空缓存区(把待输出的内容输出)的操作,而它的效率也往往更低,所以推荐用 \n 来换行,而不是 endl。(除非你想即时查看运行结果)。
9.数组
请保证在此之前至少做过20道题。
在用循环批量处理了执行语句后,还需要有方法批量处理数据,避免一个一个变量定义的情况。
int a[100]; 相当于定义了 100 个 int 变量,名字分别叫做 a[0],a[1],…,a[99]。
其中,a 称为数组的名字,[] 中的数字称为数组的下标,可以通过数组的下标访问这一排数组中的某一个变量。
因为计算机从零开始,所以定义 int a[100] 之后,下标的范围是 a[0]~a[99] 。
但是我们看着不方便,所以一般都会稍微定义大一点,比如 a[105] ,然后只用 a[1]~a[100],反正计算机内存资源还是比较充足的,浪费几个变量的空间没关系。
下标可以用变量来表示:
在 int x=5 的前提下,a[x] 等价于 a[5]。
当我们要存入一百个数据时:
int a[105];
for(int i=1;i<=100;++i)
{
cin>>a[i];
}数组定义时,[] 中一定要是具体的数字,而不能是变量。
也就是说这个句子是非法的:int x=105; int a[x]; 这种定义方法是非法的。
有的题目可能一开始不知道要输入多少个数据,比如他第一行输入一个数字 n ,第二行输入 n 个数字这样的。
这种就去找 n 的范围有多大,比如 n 的范围是 1~1000 ,那么就提前定义数组大小 int a[1005]; 保证比 n 的最大值还要大。
10.多维数组
数组不只可以像上面那样,写成编号 0~n 的变量,还可以给编号加层次:
定义 int a[15][15]; 相当于定义了 15*15 个 int 类型的变量,范围是 a[0][0]~a[14][14]。
同理,还可以 int a[15][15][15][15];。
比如 n 行 m 列的网格,每个位置输入一个数字:
int a[105][105];
for(int i=1;i<=n;++i)
{
for(int j=1;j<=m;++j)
{
cin>>a[i][j];
}
}(循环嵌套应该没有必要单独写一节了。)
数组的下标可以用来当作一种表示法,最常用的就是上面这一种:a[i][j] 表示网格中第 i 行,第 j 列上的数字是多少?
还有其他的表示法,比如:
int a[105];
for(int i=1;i<=n;++i)
{
int x;cin>>x;
a[x]++;
}在这里,a[i] 可以用来表示数字 i 出现过多少次。
如果你在代码中得到了 RE 说明你可能访问到了没有定义的地方,比如你定义了 a[100] ,然后输出了 cin>>a[200];。
P5731 【深基5.习6】蛇形方阵 这个也需要一点脑子
11.结构体
有时候一个物体不只有一个信息,比如一个学生有姓名,有学号等等。
假如一个学生有 n 条信息,要交换代表两个学生的变量,就要进行 n 次交换,非常不方便。
用结构体可以把相关的信息全部打包成一个变量:
struct student
{
string name;
int id;
};
student a,b;其中 struct 表示我要定义一个结构体,student 表示这个结构体的名字,在定义完毕之后,student 这个单词就作为一种新的变量的名字了,地位和 int 是等价的。
然后一个花括号,里面表示你要打包在一起的信息,比如姓名(字符串类型)、学号(整数类型)等。
在右括号后面接;,表示定义完毕。
然后就可以把 student 当作变量类型来定义变量了。
当我们想用到结构体中的某个信息时,用变量名+.+信息名,如输出学生 a 的姓名:
cout<<a.name<<endl;
如果我们想整体交换两个变量,可以直接:
student a,b,c;
c=a;
a=b;
b=c;结构体自带赋值功能,但是 +,-,*,/,% 还有输入输出等是不自带的(编译器不知道你自己定义的类型该怎么做加法等),需要你对结构体里的单个变量操作。
12.函数
同一项功能我们可能要用到很多次,比如选择两个数中较大的数字:
(当 if 和 for 后面不接 {} 时,默认只有后面一句话属于 if 或 for)
int a,b,c;
if(a>=b) c=a;
else c=b;这个功能我们可能要用很多次,每次都重新写不太方便,而函数可以把这个功能封装起来:
函数的形式:
int max(int x,int y)
{
int z=x;
if(x<y) z=y;
return z;
}
int main()
{
int a,b,c;
cin>>a>>b>>c;
c=max(a,b);
cout<<c<<endl;
return 0;
}前面提到过,main 是主函数,它也是一个函数,所以其他函数和它应该是并列关系。
在上面的函数里,int 是函数类型,表示使用这个函数之后会得到一个整数类型的数值。
其他函数类型还有:
bool 使用这个函数之后得到一个 bool 类型的数值。
其他变量类型也是如此。
void 使用这个函数之后不得到任何数值。
这个适用于比如交换两个变量的值这种,我们只需要交换完成,不需要有任何额外结果。
max 是函数的名字,也是使用这个函数的方法。
(int x,int y) 后面的小括号里面的是函数的参数,表示这个函数需要用哪些信息进行操作,这里表示要有两个 int 类型的参数来操作。其中 x,y 表示这两个 int 类型在这个函数里分别叫做 x 和 y 。
而参数在传入的时候,只要变量类型一致就可以,如主函数中调用 c=max(a,b) 其中 a,b 都是 int 类型,然后 a 的值会传入 x 里面,b 的值会传入 y 里面。
你还可以:
int c=max(a,5);这样 a 的值会传入 x 里面,5 会传入 y 里面。
在函数最后,有一个 return z; 表示把 z 里面的值返回函数调用的地方,也就是最后 c=max(a,b); 之后,等式右边的值就变成了这个 z 的值。
这里数值在传入的时候,x 和 a 并不是同一个变量,a 是一个盒子,x 是另一个盒子,只不过 x 这个盒子在拿过来的时候,看了一眼 a 里面的数字是多少,然后自己也装了个一样的,所以对变量 x 进行操作的时候,并不会改变 a 里面的值。
也就是说:
void work(int x)
{
x=x+5;
}
int main()
{
int a=3;
work(a);
cout<<a<<endl;
return 0;
}这样最后还是会输出 3 ,因为改变的 x 并不是 a 本身。
如果你想要在函数里改变传入的数字的值:
void work(int &x)
{
x=x+5;
}
int main()
{
int a=3;
work(a);
cout<<a<<endl;
return 0;
}这样输出的就是 8 了。
将传递参数的部分的类型后面加一个 & ,表示要将原本的变量传过来,这个叫作传引用或者传址。
相当于一份资料,只说需要的情况下,别人会给你一份复印件,在你特别声明后,别人才会给你原件。
在你自己定义的 swap 函数中,交换两个函数的值,如果不传引用,那么只是两份复印件换来换去,真正要换的东西没变。
同理,主函数也是一个 int 类型的函数,它的返回值是最后一句 return 0; 表示程序正常结束,如果返回值非零,代表异常结束。
函数可以在一个函数里面调用另一个已经定义了的函数。
int min(int a,int b)
{
if(a>=b) return b;
return a;
}
int max(int a,int b)
{
return a+b-min(a,b);
}也可以在函数里面调用自己,叫作递归:
int fac(int n)//求 n! 是多少
{
if(n==1) return 1;
return n*fac(n-1);
}跟循环同理,递归也要有一个终点,不然就会永远进行下去。
递归适用于解决一些可以把问题规模变小,但是问题本身没变的情况,比如求 n! ,我们知道 n!=n*(n-1)!,那么就可以把问题规模从 n 变到 n-1 ,而问题仍然是求阶乘,直到 1! 不需要再继续求解。
比如,求 ans = fac(3),这个函数会先让 ans=3*fac(2) ,然后 ans=3*2*fac(1) ,这时 fac(1) 的值可以直接得到,刚才引申出来的函数一层一层的返回算出来的值 1,1*2,1*2*3 ,变成 ans=3*2*1。
变量或数组可以定义在函数内部,也可以定义在函数外部
#include<bits/stdc++.h>
using namesapce std;
int a;
int aa[5];
void love()
{
int b;
}
int main()
{
int c[3];
return 0;
}这样,变量 a 和数组 aa 里面一开始都是 0 ,而变量 b 和数组 c 里面一开始是随机数。
定义在外面的变量,一开始就会被清理成 0 ,而定义在函数里面的变量,一开始里面是随机的。
13.字符串
计算机毕竟只是存数字的,所以对各种字符和字符串,都有着一些额外的操作。
对于string 类型,输入的时候是以空格或换行来区分两个变量的。
string s;
cin>>s;如果想得到字符串 s 的长度,使用库函数 int len=s.length();。
此时,字符串中的每一位存在 s[0]~s[len-1] 中。
其中,s[len] 里面一般存着一个字符 \0 ,表示这一位是一个字符的结尾,这一位通常我们用不到,但是它真实存在。
字符串中 + 代表字符串拼接:
string s,t;
cin>>s>>t;
s=s+t;
s+=t;两种加法均表示把 t 拼在 s 的后面变成一个长字符串。
但是实现有区别,第一种是先把 s 和 t 都拿出来,拼成一个字符串,再把这个字符串赋值给 s 。
第二种是直接把 t 拼在 s 后面。
显然第一种耗时要多一点。
char s[105] 也可以当一个字符串用,但是略有不同。(字符数组也可以当字符串用)
输入一个长度为 n 的字符串:
char s[105];
cin>>s;
int n=strlen(s);//这个是字符数组求字符串长度的函数。同样,s[0]~s[n-1] 中存的是字符,s[n] 中存的是 \0 表示结束标志,这一位不能被乱改。
如果修改了 s[n] 里面的 \0 ,那么各种操作就不知道字符数组在哪里结束了,比如 n=strlen(s) 的时候就会得到错误的结果。
字符数组就没有 + 操作了。
其他的字符串函数可以自己上网了解。
字符在计算机中的存储是用一个数字对应一个字符的形式,对应的规则一般是采用 ASCII 码表,可以上网查阅一下。
例如 a~z对应的数字是 97~122 而 A~Z 对应的是 65~90。
如果有一个小写字母,想把它变成大写字母,可以:
char ch;
cin>>ch;
if(ch>='a'&&ch<='z') ch=ch-'a'+'A';字典序:
字符串中比较大小的一种方法,两个字符串比较大小,先比较第一位,第一位小的字符串更小,如果前面都相同,再比较下一位。
如果前面都一样,那么长度短的字符串字典序更小。
如果长度也一样,那么两个字符串相等。